Уже сейчас решения о кредитах принимают алгоритмы, а в будущем им хотят доверить даже судебные дела И это проблема: исследования показывают, что «всемогущий» ИИ не справляется с предсказанием даже простых человеческих достижений
Едва ли не каждый день в новостях появляются сообщения об очередных успехах компьютерных алгоритмов. Они помогают ученым разобраться, как общаются слоны; предсказывают ураганы; используются банками для оценки заявок на кредиты. Может показаться, что их возможности почти безграничны — однако это впечатление обманчиво. Еще в 2020 году группа более чем из 100 ученых опубликовала статью, в которой показала — алгоритмы на основе машинного обучения очень плохо предугадывают социальные успехи — даже если речь идет о простых результатах школьных экзаменов. Спустя четыре года, 4 июля 2024 года, в Proceedings of the National Academy of Sciences (PNAS) вышла еще одна работа, которая доказала — причина этой неудачи кроется не в том, что алгоритмы были плохо натренированы или недостаточно совершенны. Выяснилось, что прогноз в принципе не может быть достаточно точным, когда речь заходит о поведении людей. Этот вывод может иметь далеко идущие последствия, учитывая как широко применяется машинное обучение сегодня — алгоритмы на его основе даже предлагают использовать в судах.
Еще несколько лет назад ученые выяснили — машинное обучение плохо предсказывает успех конкретного ученика на экзамене. Им понадобилось провести 114 интервью, чтобы показать, из-за чего так происходит и почему это важно не только для школьной статистики
Пятнадцатилетний американский школьник Чарльз всегда был вполне прилежным учеником. Хотя еще до пандемии он вынужден был получать образование дистанционно, это почти не сказалось на оценках. Однако в 9 классе он неожиданно провалился на экзаменах — его средний балл едва дотянул до «C», что в американской системе эквивалентно отметке «удовлетворительно».
В 2017 году социологи из Принстонского университета задались вопросом — можно ли предугадать подобные неожиданности? Реально ли создать алгоритм, который предсказывал бы оценку школьника на экзамене так же, как современные банковские программы рассчитывают вероятность возврата кредита для каждого конкретного заемщика? Чтобы найти ответ, они объявили о запуске специального научного проекта, в котором мог принять участие любой желающий специалист в области машинного обучения.
На призыв откликнулись больше 400 исследователей — с помощью алгоритмов им предстояло проанализировать базу данных об американских школьниках, собранную в ходе большого социологического исследования «Будущее семей и благополучие детей» (FFCWS), в котором содержатся данные о жизни почти 5000 американских детей, родившихся в период с 1998 по 2000 годы. Среди них был и Чарльз.
«Будущее семей и благополучие детей» (The Future of Families and Child Wellbeing Study) — многолетнее социологическое исследование, проводимое исследователями из Колумбийского и Принстонского университетов. Оно было запущено в 1998 году как исследование «хрупких семей» (Fragile Families) — ученые отобрали 4898 детей, родившихся у неженатых родителей, живущих в крупных (более 200 тысяч жителей) городах в период с 1998 по 2000 годы.
С тех пор исследователи периодически проводят интервью с выбранными семьями, а также оценивают успеваемость и медицинские показатели детей, их поведение и совершение ими правонраушений. Социологи встречались с участниками исследования — в год первого дня рождения ребенка, затем после того, как детям исполнялось 3, 5, 9 и 15 лет. После каждой волны данные, доступые ученым, обновлялись. В 2024 году был опубликован результат очередного этапа исследования, который пришелся на период 22-летия выбранных детей.
Большая часть собранной информации находится в открытом доступе — ее могут использовать ученые со всего мира. К середине 2024 года на основе этих данных было подготовлено почти 1,5 тысячи научных публикаций.
Участникам проекта предложили создать статистические модели, которые должны были с максимально возможной точностью предсказать для каждого из учеников к его 15-летию:
- Его средний балл на школьных экзаменах за 9 класс;
- Проявляемое ребенком прилежание;
- Столкнулась ли семья ребенка с выселением из-за неспособности оплатить жилье;
- Были ли у его родителей финансовые проблемы;
- Теряли ли они работу;
- Или, наоборот, проходили хоть какую-то профессиональную переподготовку — на курсах или в учебном заведении.
Для обучения алгоритмов участникам выделили половину доступных на тот момент данных (FFCWS), остальные использовались для проверки результатов. Однако ни одна из сделанных участниками конкурса предсказательных моделей не справилась с задачей с приемлемой точностью — жизнь оказалась слишком сложной для предсказания. Организаторы и участники опубликовали по итогам неудавшегося проекта статью — она вышла в марте 2020 года в Proceedings of the National Academy of Sciences (официальном журнале Академии наук США). Уже тогда они подчеркивали, что неожиданный неуспех машинного обучения неслучаен:
«Низкую точность прогнозирования нельзя объяснить [навыками] какого-то конкретного разработчика или ограничениями того или иного подхода [к машинному обучению]. Сотни исследователей пытались выполнить эту задачу, но никто не смог дать точный прогноз», — писали они в своей работе.
Впрочем, организаторы проекта на этом не остановились — спустя несколько лет, в июле 2024 года, в том же PNAS вышла еще одна их статья. За это время они провели 114 интервью с членами 40 семей-участниц исследования, все для того, чтобы понять, почему алгоритмы потерпели неудачу и о чем это говорит. То есть в конечном счете — установить те фундаментальные ограничения, которые не дают предсказать жизненные обстоятельства с помощью алгоритмов и статистики. И для начала (и экономии ресурсов) авторы остановились только на одном параметре — оценках за 9-й класс.
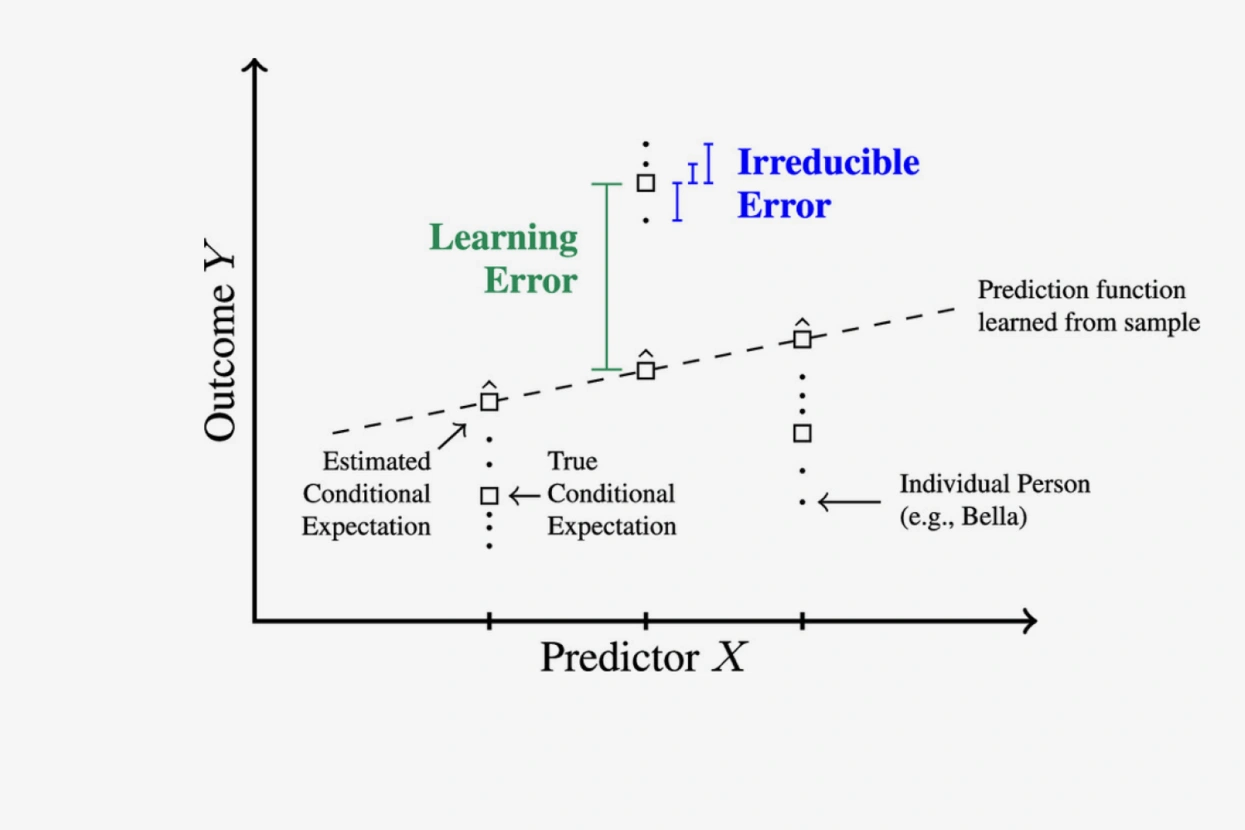
Как поняли исследователи, у алгоритмов возникло два типа проблем. Первый они назвали — неустранимыми ошибками. Они проистекают из сложности и непредсказуемости человеческой жизни и не могут быть исправлены дообучением моделей. Так, оказалось, что тот самый школьник Чарльз все время своего дистанционного обучения делал уроки в домашней столовой под присмотром родителей. Но в 9-м классе ему разрешили заниматься в подвале, где он вместо уроков играл в видеоигры. Этого события просто не было в данных, которые получил алгоритм, поэтому он и не мог учесть его в расчетах.
Другой тип проблем ученые назвали ошибками обучения. В теории их можно было бы устранить, увеличив количество данных для обучения моделей. Проблема в том, что сделать это не так просто. Чтобы алгоритм мог делать корректные выводы о связи между разными факторами жизни человека, количество случаев, на которых его обучают, должно быть как минимум сопоставимо с числом возможных параметров.
Между тем за годы существования проекта (FFCWS), социологи собрали для каждой семьи-участницы сведения о 12 942 параметрах, начиная с причин, по которым родители не вступили в брак на момент рождения ребенка, и заканчивая местом, где дети в случае необходимости получают медицинскую помощь. Даже если бы у каждого из этих параметров было только два возможных значения, число комбинаций ответов на них превышало бы количество людей, когда либо живших на Земле. Ни одно социологическое исследование не способно обеспечить алгоритму такой массив данных для обучения.
В результате, констатируют авторы исследования, возможность машинного обучения предсказывать действия людей оказывается фундаментально ограничена. Если проводить новые исследования и фиксировать все больше параметров жизни — то алгоритмы будут чаще ошибаться из-за ошибок обучения, если же сокращать количество параметров, то качество прогноза будет портиться из-за неустранимых ошибок — проще говоря, все больше значимых обстоятельств не будут отражаться в данных. И эти проблемы не решить увеличением мощности компьютеров или «скармливанием» алгоритму информации еще о нескольких тысячах людей.
«Поэтому люди, принимающие решения, — пишут авторы статьи в заключение, — должны понимать, что прогнозы [тех или иных] жизненных успехов могут быть неточны. Вне зависимости от того, созданы они людьми или алгоритмами».
«Самый важный вывод нашего исследования, — пояснил один из авторов статьи, социолог Ян Лундберг в беседе с изданием Nautilus, — заключается в том, что мы не должны слепо верить в то, что наши прогнозы [человеческого поведения] станут более точными, просто по мере увеличения вычислительных мощностей [наших компьютеров]».
Опасения авторов не случайны — вера в то, что машинное обучение может предсказывать поведение людей, распространяется все шире, его предлагают использовать даже в судах
Ян Лундберг и его коллеги не случайно подчеркивают, что их выводы не ограничены предсказанием академических успехов школьников. Речь идет о самой идее использования алгоритмов для предсказания действий и результатов людей. Уже несколько лет в академической среде активно обсуждается использование машинного обучения для того, чтобы оценивать и прогнозировать это поведение и принимать на этой основе очень важные решения об их судьбе.
Один из самых известных (и радикальных) примеров — работа 2017 года, опубликованная группой ученых под руководством известного специалиста по нейросетям Джона Клейнберга. По расчетам авторов, если решение о том, отпускать ли обвиняемых под залог или оставлять за решеткой до суда, принимали бы алгоритмы, а не судьи, это могло бы снизить «население» изоляторов почти на 40% без роста уровня преступности.
Как настаивали Клейнберг и его коллеги, это возможно как раз за счет того, что машинное обучение лучше живого судьи способно оценить личность обвиняемого и предсказать — будет ли он совершать новые преступления, если не ограничивать его свободу до суда.
Как настаивал Клейнберг в одном из своих многочисленных интервью, алгоритмы могут убрать человеческий фактор из принятия важных решений и тем самым сделать их более справедливыми.
Эти идеи по-прежнему крайне популярны среди специалистов по машинному обучению. Так, только за последние полгода свет увидело сразу несколько статей, которые посвящены использованию машинного обучения при оценке опасности рецидивов осужденных преступников, в том числе при принятии решений об их возможном досрочном освобождении (к примеру, раз и два).
Впрочем, не все исследования показывают эффективность машинного обучения для таких задач. Так, исследование немецких криминологов под руководством Сони Ецлер не выявило значимых преимуществ использования алгоритмов при попытке понять, будет ли снова совершать преступления осужденный за совершение сексуализированного насилия.
Как поясняет в разговоре с «Медузой» Иван Марков, ученый, занимающийся изучением правоприменения, тема использования машинного обучения и, говоря шире, искусственного интеллекта активно обсуждается учеными, занимающимися вопросами принятия решений. «Это то, что читается. Критикуется, но читается», — подтверждает он.
Причем, по его словам, основная критика связана даже не с ограниченной точностью предсказаний, о которой пишут Ян Лундберг и его коллеги, а с невозможностью эти решения понять и интерпретировать. Машинное обучение почти всегда подразумевает создание моделей, работающих по принципу «черного ящика», в который попадает большой набор параметров, а на выходе появляется решение. Это принципиально отличает ее от человека.
«Когда речь заходит о таких вещах, как посадка в тюрьму — это очень большая проблема. Ведь то, на что опирается судья-человек мы еще более или менее понимаем, а чем руководствуется ИИ — нет. Мы просто бросаем в натренированную модель человека и получаем результат», — поясняет Марков.
Те же модели, которые обучаются на решениях людей (касаются они выдачи кредитов или оценки склонности к домашнему насилию) неизбежно будут вбирать в себя ошибки и предвзятость человека. «Грубо говоря, если у вас все судьи расисты, то ИИ тоже станет расистом», — констатирует он.
«Искусственный интеллект хорошо приспособлен для того, чтобы удешевлять осуществление политики, которую мы уже признали успешной, проводя ее без участия человека. Но, увы, он очень плохо приспособлен к тому, чтобы что-то менять», — заключает Марков.
Отдел «Разбор»
Чарльз
Чарльз — это псевдоним, который авторы исследования используют, чтобы не раскрывать настоящее имя подростка
400
Организаторы сообщают об откликах, сделанных от 457 исследователей и 160 получивших одобрение заявках
5000
Для участия в исследовании были отобраны семьи 4898 детей.
Что за прилежание?
Этот параметр напрямую не измерялся в ходе FFCWS, организаторы проекта представили его как сумму трех факторов: результаты теста на оценку интеллекта; приветливости или неприветливости детей при встрече с родителями и склонность к хулиганским действиям — к примеру, разбиванию окон.
Какой была точность?
Предсказание даже лучших моделей оказалось лишь на 10–20% точнее, чем простое среднее, вычисленное по обучающей выборке. И даже этого удалось достичь лишь на двух метриках — среднем балле на экзамене и возникновении материальных затруднений. По остальным параметрам самые успешные модели получали лишь 3–4% к среднему по всем детям.