Facebook объявил охоту на видео с подставными лицами. Это может сделать дипфейки еще совершеннее
Facebook анонсировал конкурс Deepfake Detection Challenge. Вместе с Microsoft, MIT, Калифорнийским университетом в Беркли, Оксфордским университетом и другими исследовательскими организациями социальная сеть решила провести соревнование, участники которого должны будут разработать наиболее эффективный способ отличать deepfake-видео и фото. Об этом в официальном блоге компании написал CTO Facebook Майк Шрофер.
Facebook вложит в инициативу 10 миллионов долларов, часть из которых пойдет на призовой фонд, а остальные — на создание базы данных для обучения и тестирования алгоритмов. Отсутствие подходящего открытого набора данных, с которым инженеры могли бы работать без каких-либо юридических ограничений, является, по мнению руководства компании, одним из ключевых препятствий в деле борьбы с дипфейками.
Для создания подходящего датасета планируется пригласить актеров, подписавших соглашение на использование своего изображения, и записать с ними видеоролики, которые станут доступны участникам конкурса. Однако выкладывать их в открытый доступ не планируется: для работы с данными потребуется пройти процедуру регистрации и подписать соответствующие соглашения.
Победителей конкурса определит панель экспертов. В нее войдут специалисты из Facebook, Microsoft, правозащитной организации WITNESS и других общественных, IT и академических сообществ, которые сравнят эффективность решений разных команд.
В Facebook считают, что демократизация ИИ и последовавшая за ней волна фейков в интернете подрывают доверие к информации в Сети и ведет к дезинформации. «Фейков стало слишком много, а у индустрии нет инструмента для их выявления», — написал Шрофер. Конечная цель новой инициативы — разработать инструмент, который будет находить сгенерированные нейросетями фото и видео максимально эффективно. В день на Facebook загружают более 350 миллионов изображений, и даже маленькая погрешность при таком масштабе может повредить репутации и социальной сети, и тех людей, чье изображение использовали при создании ролика.
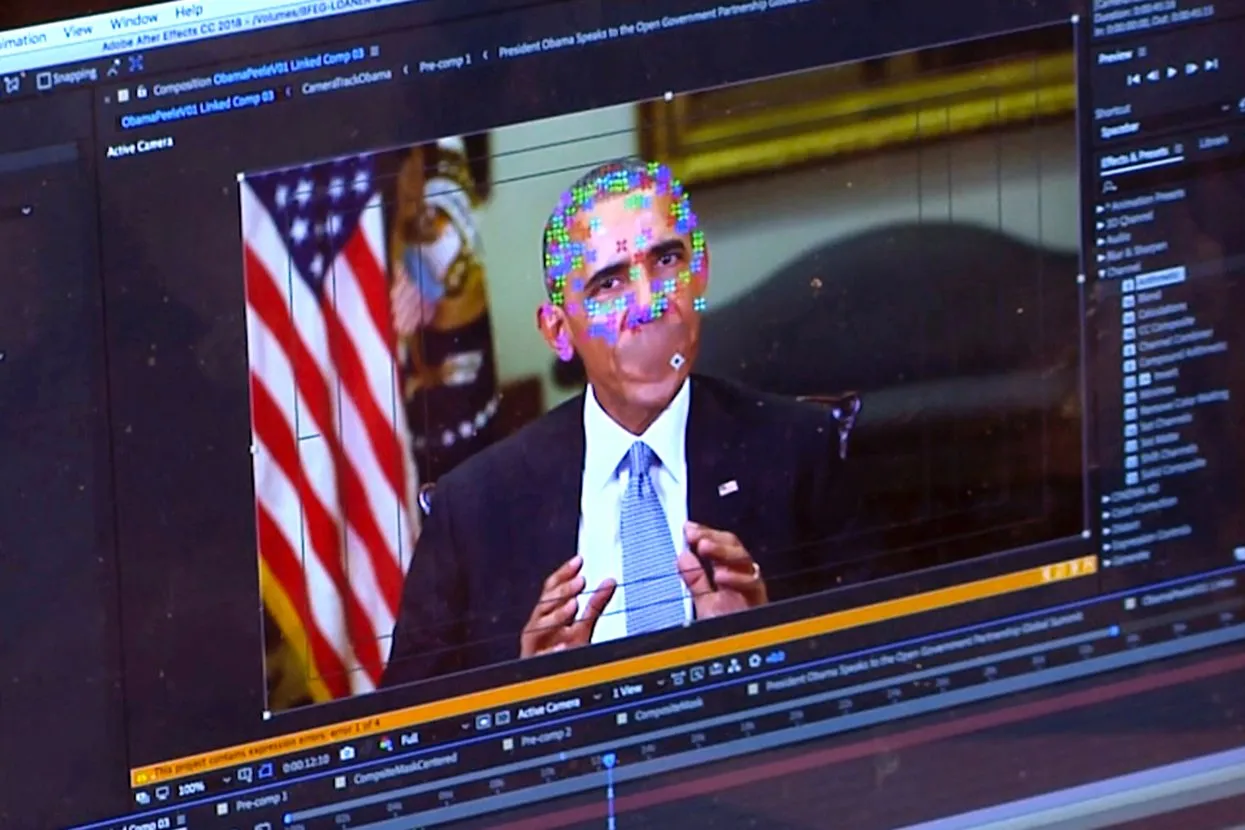
Сегодняшние инструменты с фейковыми видео и фото справляются плохо: их слишком легко обойти. О трудностях определения подделок в июне этого года изданию The Verge рассказал профессор университета Южной Калифорнии Хао Ли. Вместе с коллегами он создал алгоритм, позволяющий находить подмену в 97% случаев. Метод основан на анализе особенностей мимики, которые текущее поколение Deepfake пока не может воспроизвести. Однако Ли признался, что разработанный его командой алгоритм совсем скоро устареет — технологии создания фейков изменяются очень быстро, и методы их детекции за этим развитием не поспевают.
Deepfake Detection Challenge
VentureBeat
Сложность борьбы с фейковыми видео еще и в том, что улучшение методов детекции автоматически приводит к улучшению технологии производства фейковых видео в будущем. Дело в том, что в самой структуре алгоритма GAN, с помощью которых они генерируются, заложен принцип состязательности: одна нейросеть пытается создать фейковое видео или фото, а вторая стремится найти подделку среди настоящих роликов.Таким образом, любой метод, улучшающий технологию детекции, потенциально может быть использован для того, чтобы усовершенствовать и генеративную часть GAN. При этом борьба между детекторами и генераторами выйдет на новый уровень.
Термин deepfakes появился на Reddit в 2017 году, — это производное от двух понятий: deep learning и fake. Массовое распространение термин получил после того, как пользователь Reddit с ником deepfakes и его единомышленники начали постить порновидео с знамениостями — они прикрепляли лица последних к телам порноактеров, используя для этого алгоритмы генеративно-состязательных нейросетей. В декабре 2017-го сабреддит закрыли, а крупнейшие контентные площадки (Gfycat, Pornhub, Twitter и др.) начали активно удалять фейки со своих ресурсов. Авторов постов банили. Google даже обновил собственные правила использования сервисов: в новой версии разрешается блокировать ссылки с «синтетической порнографией».
Кирилл Тихонов